
JOIN과 JOIN FETCH를 헷갈릴 수 있다.
FROM 엔티티A JOIN FETCH 엔티티B
FROM 엔티티A JOIN 엔티티B
JOIN FETCH를 사용하면 엔티티A,엔티티B 둘 다 영속화 된다.
JOIN을 사용하면 엔티티A만 영속화 된다.
JOIN은 엔티티B를 굳이 영속화 할 이유는 없는데 엔티티B의 테이블에 있는 데이터가 필요한 경우 사용된다.
예를들어,
학생(Student)을 수학성적(Math)순으로 정렬한 데이터를 가져오고 싶다.
필요한 엔티티는 학생(Student) 엔티티이다. 수학(Math) 엔티티는 필요 없으나 ORDER BY로 정렬하려면 Math 테이블의 score 필드가 필요하다. 이런 경우에 일반 JOIN을 사용한다.
SELECT s FROM Student s JOIN s.math m ORDER BY m.score
위 JPQL을 수행하면 수학성적순으로 정렬된 학생 엔티티가 List 형태로 반환된다.
만약 수학성적 70점 이상인 경우만 조회하려면 어떻게 할까? JOIN연산에서 조건문은 ON절 쓰인다. ( JPA 2.1부터 ON절 지원, 아래 버전인 경우 WHERE 절 사용 )
SELECT s FROM Student s JOIN s.math m ON m.score >= 50 ORDER BY m.score
ON절(WHERE절)을 사용하면 원하는 대상을 필터링할 수 있다.
이런 특성 덕분에 연관관계가 없는 엔티티여도 JOIN연산으로 필터링 할 수 있다. 일반 JOIN 연산은 JOIN의 대상을 영속화하지 않기 때문에 가능한 일이다.
코드
JOIN
String jpql = "SELECT distinct t FROM Team t JOIN t.members ";
TypedQuery<Team> typedQuery = entityManager.createQuery(jpql,Team.class);
List<Team> results = typedQuery.getResultList();
일반 JOIN을 사용한 JPQL문이다.
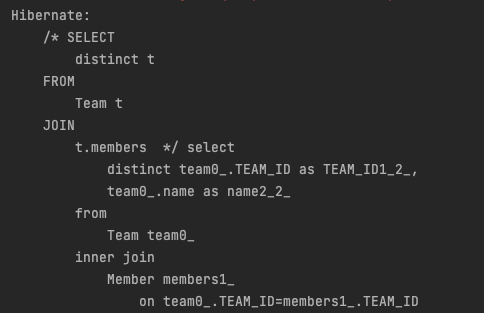
JPQL문은 위 SQL문으로 변환되어 실행된다.
JOIN은 INNER JOIN으로 변환되는데 SELECT 대상이 TEAM일뿐, JOIN된 MEMBER는 SELECT 하지 않는다. 즉, TEAM만 영속화 대상이다. 이와같이, 연관된 엔티티나 연관되지 않은 엔티티의 데이터를 기준으로 원하는 엔티티를 필터링하여 조회하고 싶을 때 사용하는 연산이 바로, JOIN 연산이다.
JOIN FETCH
String jpql = "SELECT distinct t FROM Team t JOIN FETCH t.members ";
TypedQuery<Team> typedQuery = entityManager.createQuery(jpql,Team.class);
List<Team> results = typedQuery.getResultList();
JOIN FETCH문을 사용한 JPQL문이다.
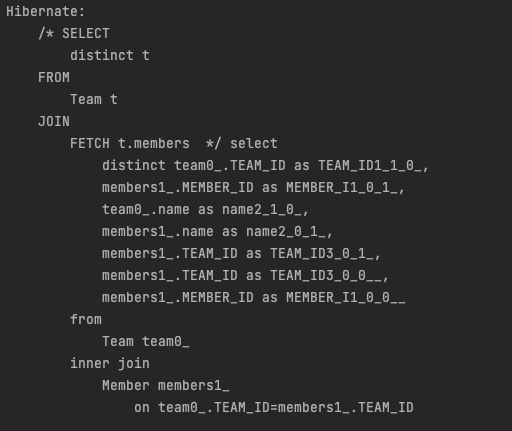
일반 JOIN과 달리, JOIN의 대상인 MEMBER 엔티티도 함께 SELECT 됨을 확인할 수 있다. JOIN FETCH는 Team 뿐만 아니라 연관된 Member까지도 함께 영속화한다.
JOIN과 JOIN FETCH는 이런 차이가 있다. 상황에 알맞는 JOIN 연산을 선택하면 된다.
참고자료
자바 ORM 표준 JPA 프로그래밍 - 기본편 - 인프런 | 강의
JPA를 처음 접하거나, 실무에서 JPA를 사용하지만 기본 이론이 부족하신 분들이 JPA의 기본 이론을 탄탄하게 학습해서 초보자도 실무에서 자신있게 JPA를 사용할 수 있습니다., - 강의 소개 | 인프런
www.inflearn.com
[JPA] 일반 Join과 Fetch Join의 차이
JPA를 사용하다 보면 바로 N+1의 문제에 마주치고 바로 Fetch Join을 접하게 됩니다. 처음 Fetch Join을 접했을 때 왜 일반 Join으로 해결하면 안되는지에 대해 명확히 정리가 안된 채로 Fetch Join을 사용했
cobbybb.tistory.com
'Dev > JPA' 카테고리의 다른 글
| [JPA] 쿼리결과 변환하기 ( JPQL 함수 ) (0) | 2023.06.14 |
|---|---|
| [JPA] 서브쿼리 ( SubQuery ) (0) | 2023.06.14 |
| [JPA] 페이징 API (0) | 2023.06.13 |
| [JPA] JPQL이란? (0) | 2023.06.13 |
| [JPA] 값타입 컬렉션 ( @ElementCollection, @CollectionTable ) (0) | 2023.06.12 |