
JPA에서 조회(SELECT)는 성능최적화가 반드시 고려되어야 한다.
엔티티는 다른 엔티티와 연관관계를 맺고 있기에 엔티티를 조회하는 과정에서 예상치 못한 쿼리가 다량으로 발생할 수 있다.( N+1 문제 ) 이번 포스팅에서는 일대일,대대일 관계(XToOne)에서의 조회API 코드를 단계별로 최적화해보겠다. 일대다관계( XToMany )는 컬렉션 개념이 추가되므로 다음 포스팅에서 다루어 보겠다.
1. 엔티티가 외부로 노출되는 코드
@GetMapping("api/v1/simple-orders")
public List<Order> orderV1(){
List<Order> all = orderRepository.findAll(new OrderSearch());
return all; // 엔티티를 외부로 반환
}
위 Controller API의 반환타입은 List<Order>이다. Order는 엔티티이다. Controller는 프레젠테이션 계층으로 외부와 통신하는 클래스이다. 엔티티는 테이블과 매핑되는 클래스로 민감한 데이터가 들어있다. 민감한 데이터를 외부로 노출시키면 안 된다.
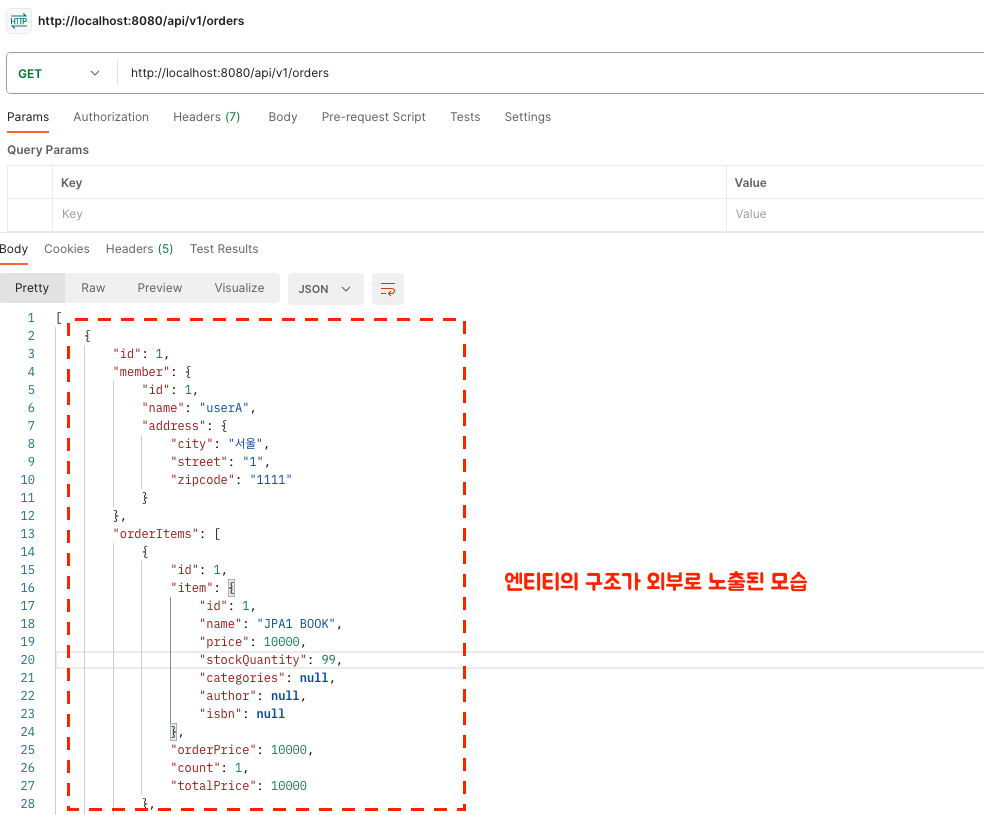
실제로 포스트맨에서 위 API를 호출하였더니 엔티티의 구조가 JSON 방식으로 그대로 노출되었다. 이는 위험하다. 그리고 화면에 불필요한 데이터까지 전송하였다. 엔티티 구조를 숨기고 화면에 필요한 데이터(Data)를 전송하려면(Transfer) 객체(Object) 하나를 만들어야 한다. 그것이 DTO(Data Transfer Object)이다.
2. DTO로 최적화하기
@GetMapping("api/v2/simple-orders") // DTO로 반환하기
public List<SimpleOrderDto> ordersV2(){
return orderRepository.findAll(new OrderSearch()).stream()
.map(SimpleOrderDto::new)
.collect(toList());
}
@Data // DTO 클래스
static class SimpleOrderDto{
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
public SimpleOrderDto(Order order){
orderId = order.getId();
name = order.getMember().getName(); // Lazy 전략인 경우, SELECT문 호출
orderDate = order.getOrderDate();
orderStatus = order.getStatus();
address = order.getDelivery().getAddress(); // Lazy 전략인 경우, SELECT문 호출
}
}
위 API는 반환타입이 List<SimpleOrderDto>이다. SELECT한 Order객체를 stream으로 OrderDto로 변환하고 반환한다. 그럼 데이터는 어떻게 조회될까? 포스트맨으로 확인해보자.
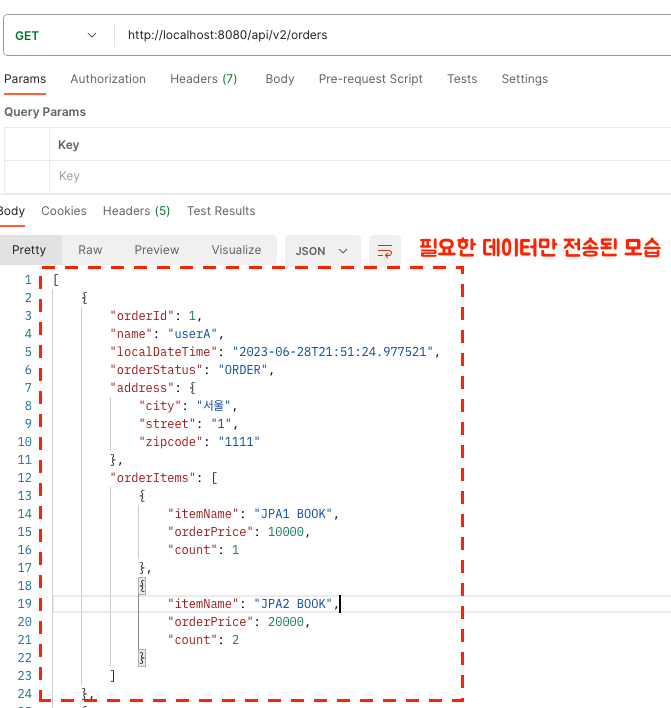
엔티티가 노출되지 않고 DTO 구조가 노출된다. DTO는 화면이 필요한 데이터만 넘기니 간결해졌다.
그러나 한 가지 문제가 있다.
Order 엔티티 리스트를 조회할 때 findAll 메소드를 호출했다.
public List<Order> findAll(OrderSearch orderSearch){
String jpql = "select o From Order o join o.member m"; // 일반 JOIN 연산
return em.createQuery(jpql, Order.class)
.setMaxResults(1000)
.getResultList();
}
JPQL은 일반 JOIN연산을 사용했다. JPQL은 오직 Order 엔티티만 조회한다. Order 엔티티가 참조하는 다른 엔티티는 가져오지 못한다. 그런데 위 DTO 생성자 코드를 보면, Order가 참조하는 Member와 Delivery 엔티티가 필요하다. Lazy 전략인 경우, Order가 Member,Delivery 엔티티의 속성을 참조할 때, 연관 엔티티를 조회하는 SELECT문이 '추가로' 실행된다. ( N+1 문제 )
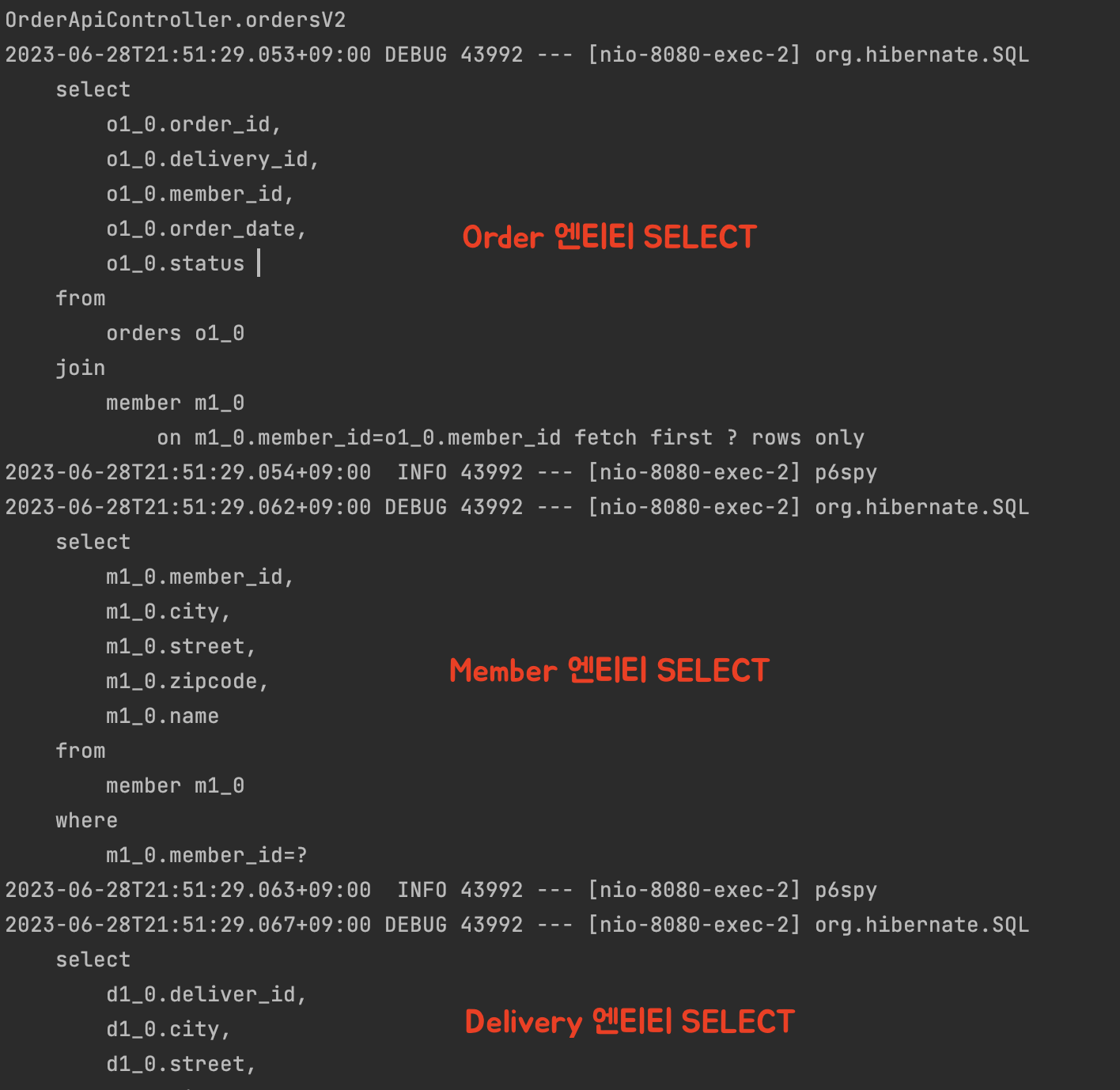
개발자는 Order를 조회하는 SELECT문 하나만 실행했는데 추가로 연속하여 SELECT문이 자동으로 실행된다. 만약 Delivery가 다른 엔티티와 연관이 되어있다면 또 다른 SELECT문 생성되고 실행된다. SELECT문이 이와 같이 많이 실행되면 성능에 좋지 못하다. 그러므로 SELECT문 실행횟수를 최대한 줄여야 한다.
3. JOIN FETCH로 최적화하기
N+1 문제를 방지하는 대표적인 방법은 JOIN FETCH(페치 조인)를 사용하는 것이다. 페치 조인은 JPQL문법으로 연관된 엔티티를 하나의 SELECT문으로 가져오는 JPQL 연산이다.
Controller API
@GetMapping("api/v3/simple-orders") // JOIN FETCH로 N+1 문제 해결 ( 성능 최적화 )
public List<SimpleOrderDto> ordersV3(){
return orderRepository.findAllWithMemberDelivery(1,100).stream()
.map(SimpleOrderDto::new)
.collect(toList());
}
Repository의 findAll 메소드가 단순 JOIN연산이었다면 findAllWithMemberDelivery 메소드는 JOIN FETCH 연산이다.
Repository 메소드
// JOIN FETCH 사용
public List<Order> findAllWithMemberDelivery() {
return em.createQuery(
"SELECT o FROM Order o" +
" JOIN FETCH o.member m "+
" JOIN FETCH o.delivery d",Order.class
).getResultList();
}
JPQL에 JOIN FETCH 연산이 사용되었음을 확인할 수 있다. 그럼 SELECT문이 몇 개 실행되었는지 확인해보자.

JOIN FETCH 연산은 엔티티와 연관된 엔티티를 모두를 하나의 SELECT문으로 가져온다. 개발자가 하나의 쿼리를 실행하면 하나의 쿼리만 실행되는 것이다. 예상치 못한 여러 개의 SELECT문이 실행되어 성능저하를 줄일 수 있다.
JOIN-FETCH는 한 가지 문제가 있다. 위 사진만 봐도 알겠지만 SELECT 되는 필드가 너무 많아진다. 연관된 엔티티의 필드를 모두 가져오기 때문에 그렇다. 그럼 SELECT되는 필드를 최적화 할 수 없을까?
4. 필드 최적화 하기
JPQL은 엔티티뿐만 아니라 특정객체(DTO)를 SELECT문으로 조회하여 생성할 수 있다. 이때는 new 연산자가 필요하다.
public List<OrderSimpleQueryDto> findOrderDtoes() {
return em.createQuery("SELECT new jpabook.jpashop.repository.order.simplequery.OrderSimpleQueryDto(o.id,m.name,o.orderDate,o.status,d.address) "
+ "FROM Order o "
+ "JOIN o.member m "
+ "JOIN o.delivery d ", OrderSimpleQueryDto.class
).getResultList();
}
( DTO클래스의 경로가 필요하므로 지저분해진다. 이는 QueryDSL을 사용하면 간단히 표현될 수 있다. QueryDSL은 나중에 다루어 보겠다.)
위 JPQL은 Order 엔티티에서 데이터를 추출하여 DTO 객체를 만드는 쿼리이다. 이때 필요한 Member 엔티티와 Delivery 엔티티의 데이터는 JOIN 연산으로 가져온다. 이렇게 구현하면 JOIN-FECTH도 필요없어진다. JOIN-FETCH가 필요했던 이유는 DTO를 구성함에 Order가 참조하는 Member와 Delivery가 필요해서였다. 그런데 JPQL에서 DTO로 SELECT문을 최적화 했기 때문에 필요한 데이터만 JOIN연산으로 가져오면 된다.
실제로 수행된 쿼리문을 보자.
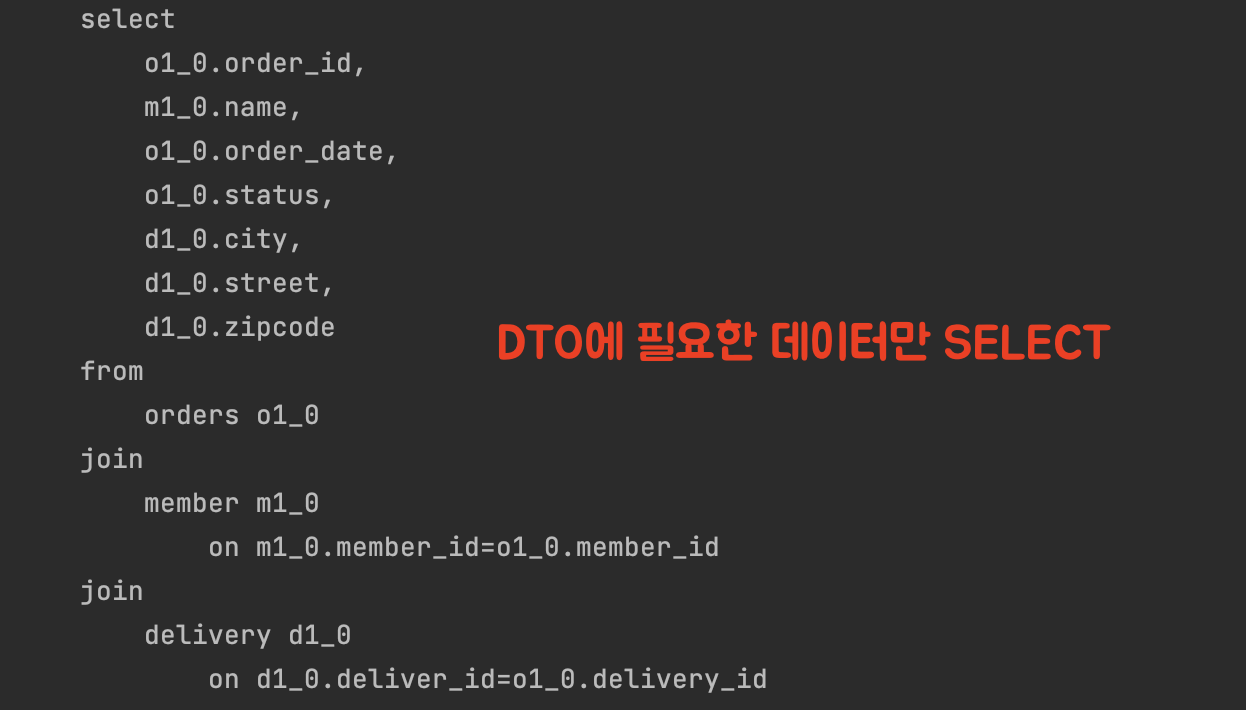
JOIN-FECTH와는 다르게, SELECT문의 필드가 훨씬 간결해졌다.
여기도 당연히 문제가 있다.
화면과 관련된 DTO가 데이터엑세스계층(Repository)까지 결합된다는 점이다. DTO는 특정화면의 스펙에 맞는 데이터를 전송하기 위한 객체이다. 특정화면에만 맞는 DTO가 데이터 엑세스 계층과 결합된다면 재사용성이 떨어진다. 다른 화면과 관련된 모듈은 해당 모듈를 사용할 수 없다.
JOIN-FETCH는 언제 사용해야 할까?
3번 JOIN-FECTH와 4번 필드 최적화는 누가 더 좋고 나쁘고의 관계가 아니다.
사실, SELECT문의 성능을 결정짓는 요소는 JOIN연산이지 조회되는 필드의 수가 아니다. 필드가 20-30개가 넘어간다면 성능최적화를 위해 4번을 고려해야 하지만, 그렇지 않다면 JOIN-FETCH로 구현하여 코드의 재사용성을 높히는 것이 좋다. 만약 4번 같이, 특정화면에 종속된 데이터엑세스계층의 모듈이 필요하다면 따로 분리해야 한다. 공동으로 사용하는 Repository와 특정화면에 종속된 Repository를 구분해야 헷갈리지 않는다.
분리하여 관리하는 특정 화면에 종속된 Repository
@Repository
@RequiredArgsConstructor
public class OrderSimpleQueryRepository {
private final EntityManager em;
public List<OrderSimpleQueryDto> findOrderDtoes() {
return em.createQuery("SELECT new jpabook.jpashop.repository.order.simplequery.OrderSimpleQueryDto(o.id,m.name,o.orderDate,o.status,d.address) "
+ "FROM Order o "
+ "JOIN o.member m "
+ "JOIN o.delivery d ", OrderSimpleQueryDto.class
).getResultList();
}
}
참고자료
실전! 스프링 부트와 JPA 활용2 - API 개발과 성능 최적화 - 인프런 | 강의
스프링 부트와 JPA를 활용해서 API를 개발합니다. 그리고 JPA 극한의 성능 최적화 방법을 학습할 수 있습니다., - 강의 소개 | 인프런
www.inflearn.com
'Dev > JPA' 카테고리의 다른 글
| [JPA] 조회API 성능최적화하기( XToMany ) (2) - default_batch_fetch_size (0) | 2023.06.29 |
|---|---|
| [JPA] 조회API 성능최적화하기 ( XToMany ) (1) - DTO, JOIN FETCH (0) | 2023.06.29 |
| [JPA] DTO의 필요성 (0) | 2023.06.28 |
| [JPA] 준영속 엔티티 수정 ( merge, DirtyChecking ) (0) | 2023.06.23 |
| [JPA] 벌크(Bulk) 연산 (0) | 2023.06.19 |