
[JPA] SpringDataJPA란?
Spring Data란? Spring Data란, Spring 프레임워크가 제공하는 추상화된 데이터 접근 기술이다. 데이터베이스나 ORM프레임워크의 종류에 따라 데이터접근방식은 다양하게 구현되지만... 사실, 기능은 거
lordofkangs.tistory.com
지난 포스팅에서 SpringDataJPA의 개념을 다루어 보았다.

SpringDataJPA는 데이터엑세스 계층의 핵심로직인 Repository를 자동생성하여 제공하는 모듈이다. Repository는 CRUD를 구현하기 위한 모듈로, 여러 Repository는 로직이 서로 중복되는 경우가 많다. 그래서 SpringDataJPA는 공통된 기능을 모아 JpaRepository 인터페이스와 SimpleJpaRepository 구현체를 제공한다.
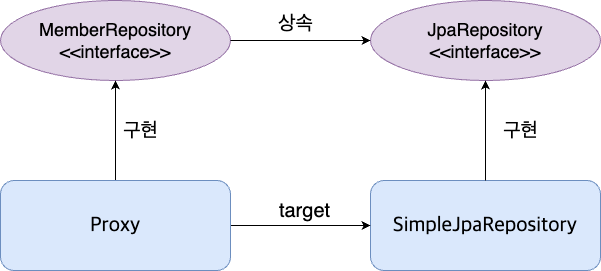
개발자는 특정 Entity에 맞는 Repository를 생성하고 JpaRepository를 implements하면 공통된 모든 기능을 사용할 수 있다. 그 이유는 SimpleJpaRepository를 target으로 한 Proxy객체가 생성되어 스프링 컨테이너에 Bean으로 등록되기 때문이다. 생성된 Proxy객체는 Repository의 구현체 역할을 하므로 적절히 DI(Dependency Injection)하여 사용하면 된다.
여기까지가 대략 지난 포스팅에 다루어 본 내용이다. 지난 포스팅에서는 공통된 기능을 제공하는 원리를 알아보았다면 이번 포스팅에서는 특정 Repository만의 CRUD로직을 구현하는 방법을 알아보겠다.
MemberRepository는 Member엔티티와 관련된 CRUD 기능을 구현해야 한다. JpaRepository에서 제공하지 않는 기능이다. Proxy 객체가 유용한 이유는 target으로한 객체의 기능과 더불어, 다른 기능도 추가로 사용할 수 있기 때문이다. MemberRepository에 정의된 기능도 Proxy객체는 사용할 수 있다. 그러나 SpringDataJPA에서 개발자는 인터페이스만 만들뿐, 구현체를 직접 만들지 않는다. 개발자는 그저 SpringDataJPA가 제공하는 Proxy객체를 사용할 뿐이다. Proxy객체는 MemberRepository에 정의된 기능이 호출되면 동적으로 기능에 맞는 구현로직을 생성하여 수행한다.
메소드 이름으로 쿼리 생성하기
SpringDataJPA는 SpringData에 의존한다. SpringData는 여러 환경의 데이터엑세스를 한 가지 추상화된 방식으로 제공하기 위한 프로젝트이다. 그런 SpringData의 하위 프로젝트가 SpringDataJPA이다. SpringData는 메소드이름을 파싱하는 모듈을 가지고 있다. 메소드 이름을 구문분석해서 적절한 쿼리를 생성하는 모듈이다.
PartTree 클래스
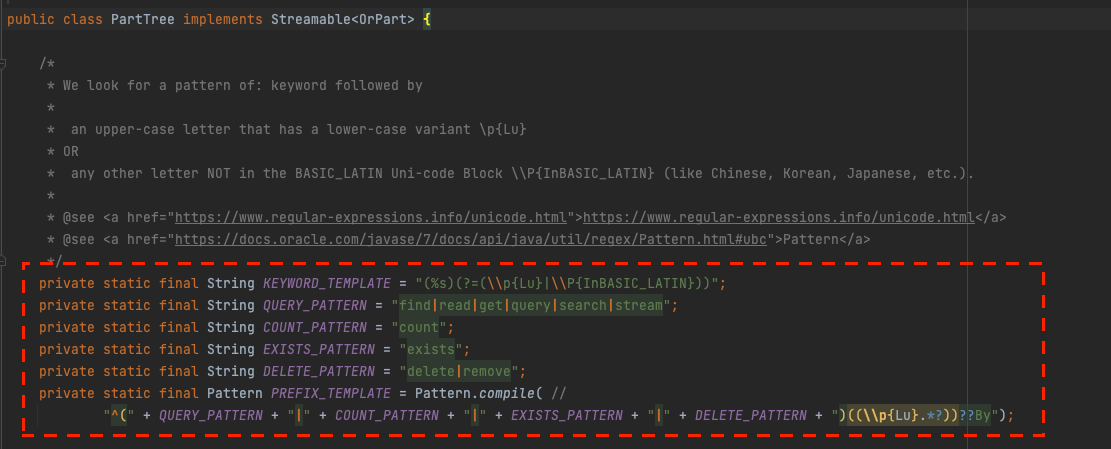
QUERY_PATTERN = "find|read|get|query|search|stream"; //SELECT문 (조회)
COUNT_PATTERN = "count"; //COUNT문 (카운트)
EXISTS_PATTERN = "exists";//Exist문 (존재유무)
DELETE_PATTERN = "delete|remove";//DELETE,REMOVE (삭제,수정)
find|read|get|query|search|stream 로 시작하는 메소드는 데이터를 조회하는 쿼리문을 자동생성한다.
count로 시작하는 메소드는 조회된 데이터의 개수를 카운트하는 쿼리문을 자동생성한다.
Exists로 시작하는 메소드는 데이터 존재 여부를 파악하는 쿼리문을 자동생성한다.
delete|update로 시작하는 메소드는 데이터를 수정하고 삭제하는 쿼리문을 자동생성한다.
이렇듯 메소드는 아래와 같은 구조로 파싱된다.
[ PATTERN ] [ 식별자 ] [ by ] [ WHERE절의 필터링 조건 ]
MemberRepository
public interface MemberRepository extends JpaRepository<Member,Long> {
List<Member> findMemberByUsernameAndAgeGreaterThan(String username, int age);
}
findMemberByUsernameAndAgeGreaterThan 메소드가 호출되면 SpringDataJPA가 메소드이름을 파싱하여 적절한 쿼리를 동적으로 생성한다. find이니 SELECT 조회문이고 Member는 다른 메소드와 구분하기위한 식별자이고 By 뒤부터는 WHERE에 들어갈 필터링 조건이 들어간다. ByUsername은 파라미터로 받은 username과 동일한 데이터를 조회한다는 의미이고 AgeGreaterThan은 파라미터로 받은 age보다 큰값인 데이터를 조회한다는 의미이다.
자동생성되어 실행된 쿼리문
select
m1_0.member_id,
m1_0.age,
m1_0.created_by,
m1_0.created_date,
m1_0.last_modified_by,
m1_0.team_id,
m1_0.updated_date,
m1_0.username
from
member m1_0
where
m1_0.username=?
and m1_0.age>?
실제로 SELECT문이 실행되었음을 로그로 확인할 수 있다. 여기서 간단한 페이징기능도 구현할 수 있다.
public interface MemberRepository extends JpaRepository<Member,Long> {
List<Member> findTop3HelloBy(); // Top3은 limit 3을 의미한다.
}
Top3는 limit 3을 의미한다. limit 3은 반환되는 행을 3개로 제한하는 연산으로 최대 3개 행만 반환한다.
자동생성되어 실행된 쿼리문
select
m1_0.member_id,
m1_0.age,
m1_0.created_by,
m1_0.created_date,
m1_0.last_modified_by,
m1_0.team_id,
m1_0.updated_date,
m1_0.username
from
member m1_0 fetch first ? rows only
이렇듯 개발자는 메소드 이름만 규약에 맞게 작성했을 뿐인데, 자동으로 쿼리문이 생성되었다.
Spring Data JPA - Reference Documentation
Example 121. Using @Transactional at query methods @Transactional(readOnly = true) interface UserRepository extends JpaRepository { List findByLastname(String lastname); @Modifying @Transactional @Query("delete from User u where u.active = false") void del
docs.spring.io
( 메소드이름 작성방식은 위 레퍼런스를 참고하면 된다. )
이처럼 JpaRepository가 제공하지 않는 기능일지라도 메소드 이름만 잘 작성하면 SpringDataJPA가 알아서 자동으로 쿼리문을 생성한다. 그러나 이런 방식은 단순한 쿼리 생성이 필요한 경우에는 유용하지만 복잡한 쿼리를 생성해야 되는 경우에는 구현하기 어려워진다. 쿼리가 복잡해지면 JPQL로 직접 작성하는 것이 좋다.
그러면 개발자가 JPQL이 작성된 메소드를 직접 구현해야 할까?
아니다! 스프링데이터JPA는 @Query 어노테이션을 제공한다. @Query 어노테이션에 실행할 JPQL만 넣어주면 된다. 그러면 메소드가 실행될 때, 프록시 객체가 JPQL을 반영한 메소드 로직을 구현하여 실행한다. 자세한 내용은 다음 포스팅에서 다루어 보겠다.
참고자료
실전! 스프링 데이터 JPA - 인프런 | 강의
스프링 데이터 JPA는 기존의 한계를 넘어 마치 마법처럼 리포지토리에 구현 클래스 없이 인터페이스만으로 개발을 완료할 수 있습니다. 그리고 반복 개발해온 기본 CRUD 기능도 모두 제공합니다.
www.inflearn.com
'Dev > JPA' 카테고리의 다른 글
| [SpringDataJPA] 페이징 ( Pageable, Page, Slice ) (0) | 2023.07.12 |
|---|---|
| [SpringDataJPA] @Query (0) | 2023.07.11 |
| [SpringDataJPA] SpringDataJPA란? (0) | 2023.07.06 |
| [JPA] OSIV ( Open Session In View ) (0) | 2023.06.30 |
| [JPA] 조회API 성능최적화하기( XToMany ) (3) - DTO 직접조회 (0) | 2023.06.29 |