
[QueryDSL] QueryDSL 동작원리(1) - 빌더패턴
JPA에서 개발자가 원하는 엔티티를 얻으려면, JPQL을 작성하고 이를 EntityManager로 실행해야 한다. 이때 한 가지가 문제가 있는데, JPQL이 문자열이라는 점이다. JPQL이 문자열이기에 타입안정성 체크
lordofkangs.tistory.com
지난 포스팅에서 QueryDSL이 빌더패턴 구조로 이루어진 이유에 대해서 다루어 보았다 . 이번 포스팅에서는 빌더패턴이 어떤 방식으로 구현되어 있는지 알아보겠다.

개발자가 문자열로 JPQL을 작성하면 타입 안정성 체크가 어렵고 동적 쿼리 생성이 직관적이지 못하다. 이를 위해, QueryDSL은 JPQL 생성및실행 권한을 자신에게 위임하고 개발자는 JPQL 생성에 필요한 데이터 설정만 하도록 지원한다. QueryDSL은 개발자가 데이터를 유연하게 설정할 수 있도록 빌더패턴 구조로 이루어져 있다.
빌더패턴 다이어그램
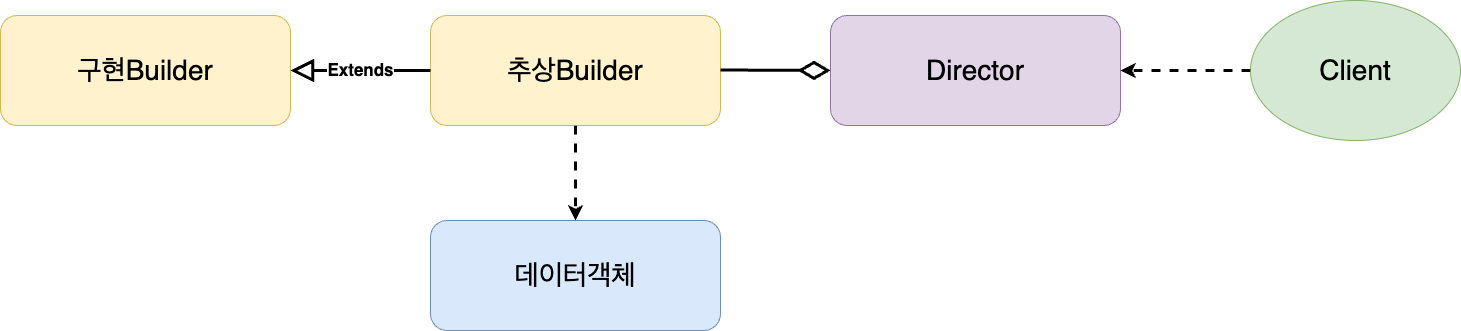
그럼 간단히 빌더패턴 구조에 대해서 알아보자.
클라이언트가 특정 객체에 데이터 설정을 하려고 한다. 클라이언트가 직접 데이터객체에 접근하면 유연한 데이터 설정을 못하니 Builder 객체의 도움이 필요하다. 데이터 설정은 Builder객체의 역할이지만 클라이언트 친화적인 구조는 아니다. 클라이언트 친화적 설정이 가능하도록, Builder와 Client사이에 Director 객체를 둔다. 그리고 Director객체가 Builder 객체와 집합관계를 맺어 Director가 Builder 기능을 사용할 수 있도록 한다. 여기서 집합관계란 연관관계인데 서로 생명주기가 다른 연관관계를 의미한다.
[OOP] 빌더 패턴 ( Builder Pattern )
디자인 패턴이란? 객체지향설계 과정에서 발생하는 문제들을 해결하기 위한 패턴(Pattern) 문제 상황 필드변수가 많은 객체는 상황에 따라 세팅이 필요한 변수도 있고 필요하지 않은 변수도 있다.
lordofkangs.tistory.com
( 자세한 설명이 필요하다면 위 포스팅을 참고하기를 바란다. )
Builder 패턴은 위와 같은 구조로 이루어져 있다. 그럼 이를 QueryDSL로 대응해보자.
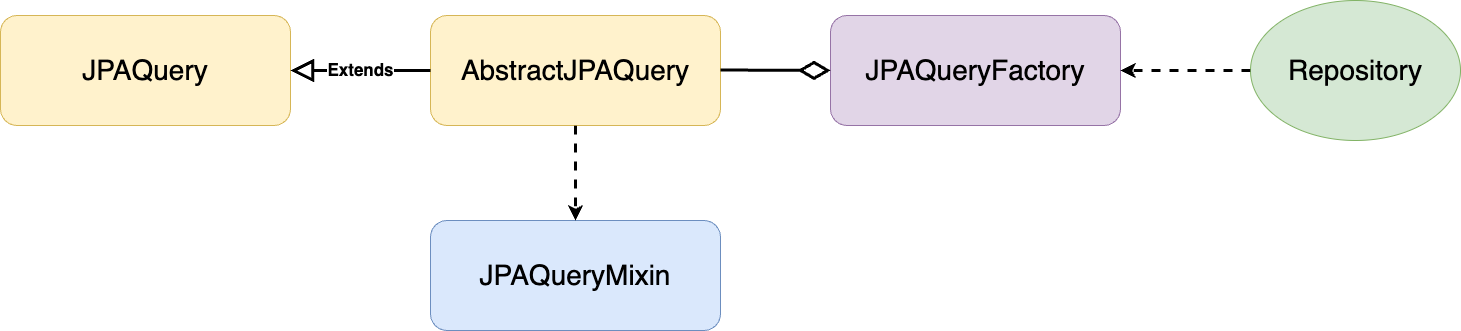
JPAQueryFactory ( Director )
public class MemberRepositoryImpl implements MemberRepositoryCustom{
private final JPAQueryFactory queryFactory;
public MemberRepositoryImpl(EntityManager entityManager){
this.queryFactory = new JPAQueryFactory(entityManager);
}
// 중략...
}
JPAQueryFactory는 빌드 패턴의 Director 기능을 하는 객체이다. Builder를 클라이언트 친화적이게 사용할 수 있도록 하는 중간 객체라 할 수 있다.
public List<Member> searchMember(MemberSearchCondition condition){
QMember qMember = QMember.member;
return queryFactory
.select(qMember) //select 메소드
.from(qMember) // from 메소드
.leftJoin(member.team, team) // leftJoin 메소드
.where( //where 메소드
usernameEq(condition.getUsername()),
teamNameEq(condition.getTeamName()),
ageGoe(condition.getAgeGoe()),
ageLoe(condition.getAgeLoe())
)
.fetch(); //fetch 메소드
}
Query 설정을 SELECT절, FROM절, WHERE절 순으로 이루어져야 가독성이 올라가고 클라이언트 친화적이라 할 수 있다. JPAQueryFactory는 쿼리설정을 select메소드, update메소드, insert메소드, delete메소드로 시작하도록 지원하는 Director 객체이다. 클라인언트가 Director 없이 Builder에 바로 접근한다면 데이터 설정 방법이 너무나 다양해지고 중구난방이 되어버린다. 약속된 순서와 규칙으로 데이터 설정을 유도하기 위해 Director객체가 필요하다. QueryDSL에서는 JPAQueryFactory가 그 역할을 한다. JPA에서 QueryDSL의 클라이언트는 Repository 객체이다. Repository는 JPAQueryFactory에 접근하여 JPAQueryFactory가 제공하는 기능으로만 데이터 설정을 할 수 있다.
AbstractJPAQuery ( Builder )
Director에게 기능을 제공하는 Builder는 AbstractJPAQuery이다.
AbstractJPAQuery는 데이터를 유연하게 설정할 수 있는 메소드 체이닝 방식을 제공한다. 위 코드를 보면, select 메소드, from 메소드 , leftJoin 메소드, from 메소드가 '.' 연산자로 일렬 구조로 이루어져 있다. 이와 같은 구조를 메소드체이닝 구조라고 하는데, 빌더패턴 구조의 가장 큰 특징이다.
AbstractJPAQuery 클래스는 메소드의 반환타입을 AbstractJPAQuery, 자신으로 통일하였다. 그래야 메소드가 자기객체(this)를 반환하고 다른 메소드를 체인구조로 호출할 수 있기 때문이다.
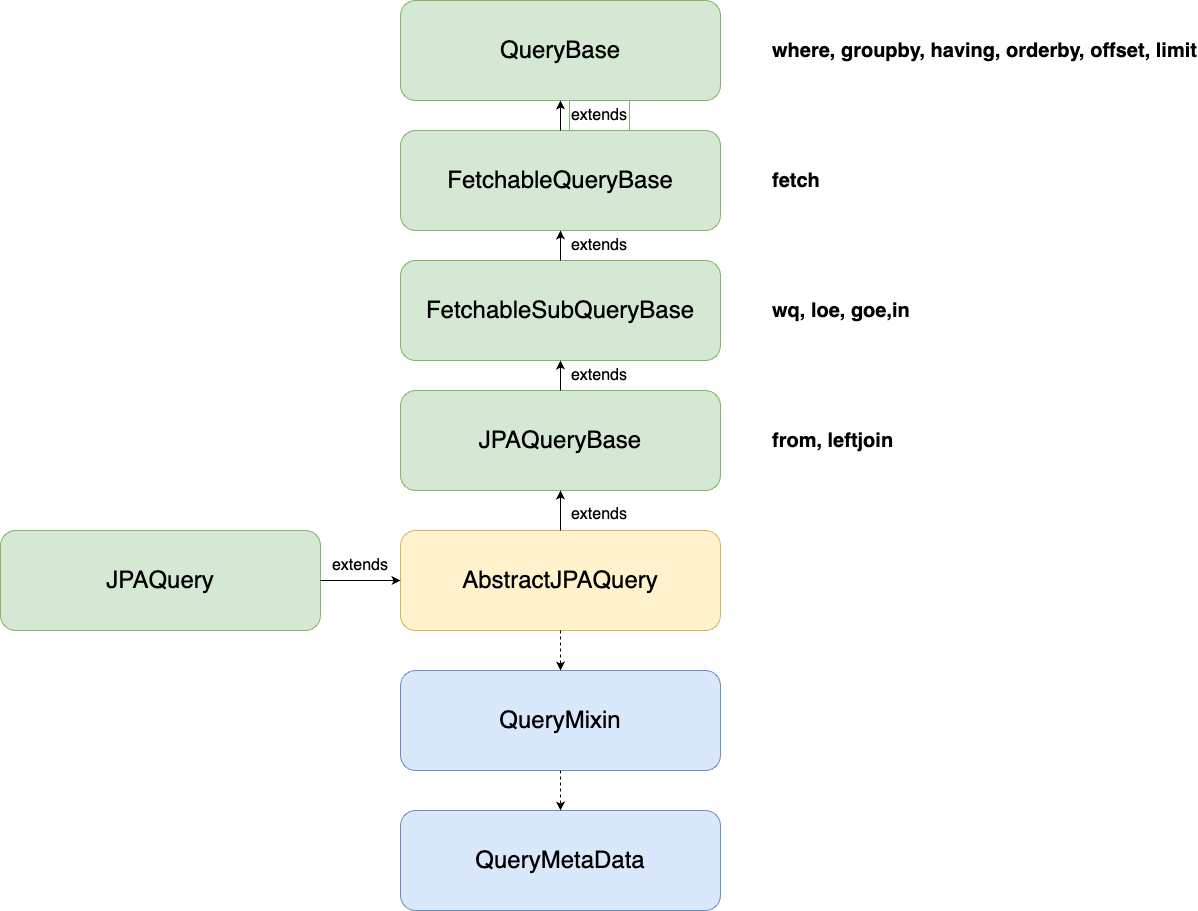
AbstractJPAQuery는 추상클래스로 JPAQuery 클래스가 구현 클래스이다.
AbstractJPAQuery는 JPQL에 필요한 데이터를 설정할 수 있는 메소드를 다양하게 제공하는데, 이것이 가능한 이유는 다양한 클래스를 상속하고 있어서이다. 부모클래스로부터 다양한 메소드를 가져와 Override하거나 그대로 사용하여, 다양한 데이터 설정이 가능해진다.
여기서 주의할 점은,
AbstractJPAQuery는 데이터설정을 메소드 체이닝 방식으로 구현하기 위한 Builder일 뿐, 실제 데이터가 저장되는 공간은 아니다.
QueryMixin
public class JPAQuery<T> extends AbstractJPAQuery<T, JPAQuery<T>> {
//중략...
@Override
public <U> JPAQuery<U> select(Expression<U> expr) {
queryMixin.setProjection(expr); //QueryMixin에 데이터 설정
JPAQuery<U> newType = (JPAQuery<U>) this; // 메소드 체이닝을 위한 본인(this) 반환
return newType; //
}
//중략...
}
AbstractJPAQuery의 구현 클래스인 JPAQuery의 select 메소드를 보자. QueryMinin 객체의 setter함수에 데이터를 설정함을 알 수 있다. AbstractJPAQuery로 들어온 모든 데이터는 QueryMinin에 설정된다. 정리하면, Repository(클라이언트)와 QueryMixin(데이터객체)사이에 AbstractJPAQuery(Builder)가 들어가 메소드 체이닝 방식으로 유연한 데이터 설정이 가능해지고, JPAQueryFactory(Director)로 인해 약속된 순서로 데이터 설정이 가능해지는 것이다.
그러나 QueryMixin은 실제 데이터가 저장되는 공간은 아니다. 사실, 한 가지 객체가 더 있다. 바로 QueryMetaData 객체이다. 실제 데이터가 저장되는 자료구조가 있는 공간은 QueryMetaData이다.
QueryMetaData 인터페이스의 구현 클래스
public class DefaultQueryMetadata implements QueryMetadata, Cloneable {
// 중략...
private Set<Expression<?>> exprInJoins = new LinkedHashSet<>();
private List<Expression<?>> groupBy = new ArrayList<>();
private Predicate having;
private List<JoinExpression> joins = new ArrayList<>();
private Expression<?> joinTarget;
private JoinType joinType;
@Nullable
private Predicate joinCondition;
private Set<JoinFlag> joinFlags = new LinkedHashSet<>();
private QueryModifiers modifiers = QueryModifiers.EMPTY;
private List<OrderSpecifier<?>> orderBy = new ArrayList<>();
private Expression<?> projection;
private Map<ParamExpression<?>, Object> params = new LinkedHashMap<>();
private boolean unique;
private Predicate where;
private Set<QueryFlag> flags = new LinkedHashSet<>();
private boolean extractParams = true;
private boolean validate = false;
private ValidatingVisitor validatingVisitor = ValidatingVisitor.DEFAULT;
//중략...
}( 위 코드는 이해를 위해 필요한 부분만 발췌한 코드입니다. )
QueryMetaData 인터페이스의 구현 클래스이다. 다양한 자료구조가 존재한다. JPQL에 생성에 필요한 데이터는 용도에 맞는 자료구조에 저장된다. 이렇듯 다양한 자료구조가 있다보니 다양한 데이터 타입과 다양한 setter함수가 존재한다. 이로인해 데이터 설정은 복잡해질 수 밖에 없다. Builder는 메소드 체이닝 구현을 위해 존재하는 클래스이지, 이런 복잡한 설정을 위해 존재하지 않는다.
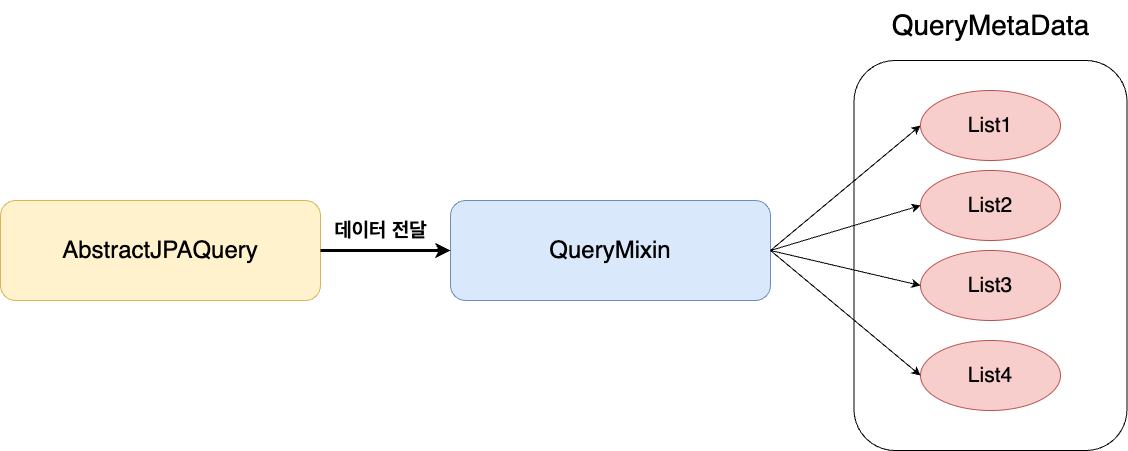
데이터 설정 작업을 QueryMixin으로 분리하면 Builder인 AbstractJPAQuery는 QueryMixin에게 데이터만 전달하면 된다. QueryMixin은 전달받은 데이터를 자료구조에 맞도록 정제하고 적합한 setter함수를 호출하여 실제 자료구조에 데이터를 저장하는 작업을 진행한다.
QueryMixin 클래스
public class QueryMixin<T> {
private final QueryMetadata metadata; // 자료구조를 가진 QueryMetadata
public final T from(Expression<?> arg) {
metadata.addJoin(JoinType.DEFAULT, arg);
return self;
}
public final QueryMetadata getMetadata() {
return metadata;
}
public final T groupBy(Expression<?> e) {
e = convert(e, Role.GROUP_BY);
metadata.addGroupBy(e);
return self;
}
public final T having(Predicate e) {
metadata.addHaving(convert(e, Role.HAVING));
return self;
}
public final <P> T innerJoin(Expression<P> target) {
metadata.addJoin(JoinType.INNERJOIN, target);
return self;
}
public final T limit(long limit) {
metadata.setLimit(limit);
return self;
}
public final T offset(long offset) {
metadata.setOffset(offset);
return self;
}
public final T on(Predicate condition) {
metadata.addJoinCondition(convert(condition, Role.FROM));
return self;
}
public final T where(Predicate e) {
metadata.addWhere(convert(e, Role.WHERE));
return self;
}
}( 위 코드는 이해를 위해 필요한 부분만 발췌한 코드입니다. )
위 코드를 보면 알 수 있듯, QueryMixin은 데이터를 정제하여 setter 함수로 데이터를 자료구조에 저장한다.
그럼 처음부터 하나씩 정리해보자.
1. 개발자(클라이언트)가 문자열로 JPQL을 작성하면 타입안정성 체크가 어렵고 동적쿼리를 직관적으로 생성하지 못한다.
2. 이런 문제를 해결하기 위해 QueryDSL 프레임워크를 사용한다.
3. QueryDSL은 JPQL 생성및실행 업무를 담당하는 프레임워크로, 개발자는 JPQL 생성에 필요한 데이터만 설정하면 된다.
4. JPQL 데이터 설정을 유연하게 하기 위해, QueryDSL은 빌드패턴 구조로 이루어져 있다.
5. JPAQueryFactory는 빌더패턴의 Director 객체로, 클라이언트가 약속된 순서 데이터를 설정할 수 있도록 도와준다.
6. AbstractJPAQuery는 빌더패턴의 Builder 객체로, 메소드 체이닝 방식으로 데이터 설정을 가능하게 만든다.
7. QueryMixin은 Builder가 데이터 설정을 단순하게 할 수 있도록, AbstractJPAQuery와 QueryMetaData 사이에서 중간 다리 역할을 한다.
여기까지 완료되면 JPQL 생성을 위한 메타데이터 설정이 끝이 난다. 메타데이터 설정이 끝나면 이를 활용하여 JPQL을 생성 및 실행 후, 클라이언트가 원하는 결과를 반환해야 한다.
public List<Member> searchMember(MemberSearchCondition condition){
QMember qMember = QMember.member;
return queryFactory
//JPQL 메타데이터 설정 시작
.select(qMember) //select절 데이터
.from(qMember) // from절 데이터
.leftJoin(member.team, team) // leftJoin절 데이터
.where( //where절 데이터
usernameEq(condition.getUsername()),
teamNameEq(condition.getTeamName()),
ageGoe(condition.getAgeGoe()),
ageLoe(condition.getAgeLoe())
)
// JPQL 메타데이터 설정 끝
// JPQL 생성 및 실행 시작
.fetch();
}
JPQL 생성및실행을 명령하는 메소드가 fetch 메소드이다. 다음 포스팅에서는 fetch 메소드를 알아보도록 하겠다.
'Dev > JPA' 카테고리의 다른 글
| [QueryDSL] Expression( 표현 ) (0) | 2023.08.04 |
|---|---|
| [QueryDSL] QueryDSL 동작원리(3) - fetch (0) | 2023.08.02 |
| [QueryDSL] QueryDSL 동작원리(1) - 빌더패턴 (0) | 2023.07.28 |
| [QueryDSL] QueryDSL 설정하기 ( SpringBoot 2.6이상, SpringBoot 3.x ) (3) | 2023.07.26 |
| [QueryDSL] QueryDSL이란? (0) | 2023.07.21 |