
인간과 컴퓨터가 대화하려면
어떻게 할까?
인간의 언어는
문자, 이미지, 동영상, 소리 등이 있다.
그러나
컴퓨터는 1과 0밖에 모른다.
그러므로
우리는 문자, 이미지, 동영상, 소리를
1과 0에 대응하여 표현해야 한다.
문자표(Character Set)
특히 문자를 1과 0으로 표현하려면
문자표가 있어야 한다.
대표적인 문자표는
'아스키 코드표'가 있다.

아스키 코드표는
7bit가 만들어 낼 수 있는 이진수 조합을
문자와 대응한 표이다.
총 128가지 표현 가능하다.
하지만
128가지는 영어 알파벳 표현에는 문제 없지만
세계 각국의 문자 표현은 불가능하다.
그래서 탄생한 것이
16bit를 활용한 유니코드이다.

유니코드는 16bit이기에
216가지, 즉 65536가지 문자 표현이 가능하다.
16비트 고정폭으로 문자를 표현하는
UCS-2가 등장했다.
그러나
아직도 전 세계 문자를
담기에는 부족하다.
그래서 32bit로 늘리려고 시도했으나
32bit는 문자 하나를 표현하기에는
메모리를 너무 많이 차지했다.
UTF-16
인코딩이란
문자표가 더 이상 수용 못하는 문자들을
수용하기 위한 여러가지 시도들을 의미한다.

32bit는 너무 크니,
16bit를 유지하는 대신
언어판을 늘리는 것이다.
언어판을 17개까지 늘려
총 17 x 65536가지의 문자 표현이 가능해졌다.
가장 맨 앞에 있는 언어판은 가장 자주 사용되는 기본 언어판(BMP)이다. 우리 한글도 이 곳에 포함된다. 기본 언어판에 있는 문자들은 16bit로 표현 가능하다. 그러나 기본 언어판에 없는 문자들은 다른 언어판에서 찾아야 한다. 그러므로 다른 언어판을 가리키는 메타데이터가 포함되어야 한다. 이는 데이터의 길이는 16bit + a로 가변적으로 변하게 한다..
이렇게 UCS-2 문자표를 활용하여, 기본 문자들은 16bit를 사용하고 그 외 문자는 가변적으로 변하는 방식을 두고 UTF-16 인코딩 방식이라 부른다.
그러나 문제가 하나 더 있다.

UTF-16은 영어와 숫자를 표현하는데
16bit나 사용한다.
'W'를 표현하는데
맨 앞의 8bit는 아무 의미없이
공간만 차지한다.
아스키 코드는
7bit면 표현이 가능했는데 말이다.
그리고 컴퓨터에서 사용되는
대부분의 언어는 영어와 숫자다.
그러므로 UTF-16은
공간의 비효율을 초래할 수 있다.
UTF-8
UTF-8 인코딩 방식은
UCS-2 문자표를 토대로
데이터를 재가공하여
UTF-16의 한계를 보완한다.
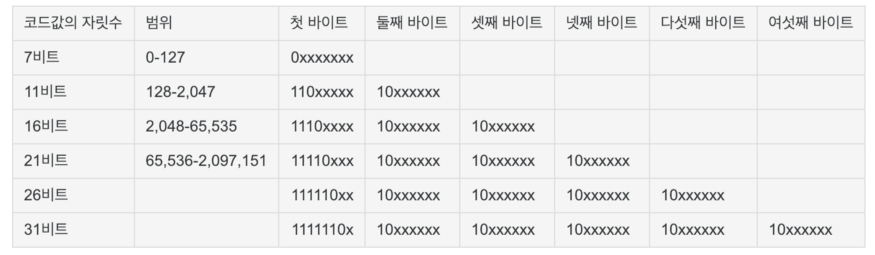
UTF-8의 데이터 표현 방식이다.
규칙은 복잡하니 굳이 이해 안해도 된다.
결국 이 모든 규칙은
7bit로 표현 가능한 문자를
7bit로 표현하기 위함이다.
나머지 문자는 희생된다.
한글은 UTF-16에서 2byte지만 UTF-8에서는 3byte를 차지한다. 아스키 코드 문자들을 7bit 데이터로 표현하기 위해서, 나머지 문자 데이터에 메타데이터가 붙는 것이다. 그래서 UTF-8은 데이터의 크기가 8bit + a 로 가변적으로 변한다.
그러므로 인코딩 방식은 상황에 따라 잘 선택하는 것이 좋다. 아스키 코드 문자 안에서 주로 문자가 사용된다면 UTF-8 인코딩 방식이 유리하다. 반면에 아스키 코드 문자를 벗어나는 문자를 사용하면 UTF-16이 유리할 수 있다. 실제로 JAVA의 JVM은 문자열을 메모리에 저장할 때, UTF-16 인코딩 방식을 사용한다. 관련해서는 다음 포스팅에서 다루어 보겠다.
'Dev > JAVA' 카테고리의 다른 글
| [ JAVA ] 스트림이란? ( 바이트 기반 스트림 , 문자 기반 스트림 ) (0) | 2021.07.08 |
|---|---|
| [ JAVA ] JVM이 문자열을 UTF-16 방식으로 저장하는 이유 (3) | 2021.07.06 |
| [ JAVA ] 바이트 스트림 vs 문자 스트림 (0) | 2021.06.30 |
| [ JAVA ] 제네릭 (Generic) 심화 ( 와일드 카드 + 상속 ) (0) | 2021.06.20 |
| [ JAVA ] 제네릭 (Generic) (0) | 2021.06.20 |