
프로그래밍 분야에서는 시간-공간 트레이드-오프(Trade-off) 현상이 자주 일어난다.
처리시간을 줄이면 처리공간이 늘어나고 처리공간이 줄어들면 처리시간이 늘어나는 현상이다. 세그먼트 트리(Segement Tree)는 공간을 늘리고 시간을 줄인 알고리즘이다.
5 8 7 3 2 5 1 8 9 8 7 3
세그먼트 트리가 필요한 이유는 수열의 구간합 테이블을 더 빠른속도로 구현하기 위함이다. 노드의 개수가 N일때 구간합테이블을 배열로 구성하면 N개의 노드가 필요하지만 시간복잡도는 O(N)이다. 반면 세그먼트 트리로 구성하면 최대 4xN개 노드가 필요하지만 시간복잡도는 O(logN)이다. ( 4xN개의 노드가 필요한 이유는 밑에서 다루어 보겠다. )
그러므로 수열의 변경이 자주 일어나 구간합테이블이 자주 변경된다면 속도가 빠른 세그먼트 트리로, 수열의 변경이 자주 일어나지 않는다면 메모리를 적게 차지하는 배열로 구성하는 것이 좋다.
세그먼트 트리 ( Segment Tree ) 구현

세그먼트 트리는 이진트리(Binary Tree)이다. 이진트리의 리프노드에는 수열의 값이 차례로 들어가 있다.
5 8 7 3 2 5 1 8 9 8 7 3
리프노드에서 위로 올라가면서 합이 이루어진다. 그리고 마지막 루트노드에는 전구간 합이 들어간다. 리프노드를 제외한 나머지 노드에는 구간별 합이 들어가 있다. 세그먼트 트리는 구간을 분할한 후 다시 합치는 방식으로 구현되므로 재귀호출(Recursive Call)로 구현된다.
arr = list(map(int,input().split())) #수열
tree = [0]*(len(arr)*4) #세그먼트트리
#세그먼트트리 구현함수
def init_tree(start,end,node) :
if start == end : #리프노드인 경우
tree[node] = arr[start]
return tree[node]
#리프노드가 아닌경우
mid = (start+end)//2 #중간지점
tree[node] = init_tree(start,mid,2*node) + init_tree(mid+1,end,2*node+1) #재귀호출
return tree[node]
init_tree(0,len(arr)-1,1) # 전구간 , 루트노드 인덱스
print(tree)
재귀호출 함수는 파라미터로 start,end,node를 갖는다. start-end는 구간을 의미한다. 그리고 node는 [start-end] 구간의 합이 저장된 트리의 위치를 의미한다. 이진트리는 좌측노드가 2*n, 우측노드가 2*n+1이다. 그래서 루트노드를 1로 지정해야 좌우노드에 인덱스지정이 간편해진다.
init_tree(0,len(arr)-1,1)
전 구간의 합이 저장된 트리의 위치가 인덱스 1이라는 의미이다. 이제 구간을 분할해보자. 구간은 start와 end의 중간지점(mid)를 기준으로 분할한다. 중간지점을 기준으로 구간을 반씩 분할하는데, start와 end가 같아지는 지점까지 분할한다. start와 end가 같아지는 지점은 리프노드이다. 세그먼트 트리를 이해하려면, 구간과 트리의 node를 매핑하여 이해해야 한다. start-end 구간의 합은 node 위치에 저장되어 있음을 잊지말자.
세그먼트 트리의 목적은 잦은 수열의 변경에서 빠른속도로 구간합을 구함에 있다. 그럼 구간합을 구하는 로직과 세그먼트 트리를 UPDATE하는 로직이 필요하다. 이는 다음 포스팅에서 다루어 보겠다.
+ 노드의 개수가 4xN인 이유
만약에 리프노드가 2ⁿ 개라면 '완전이진트리' 이다.
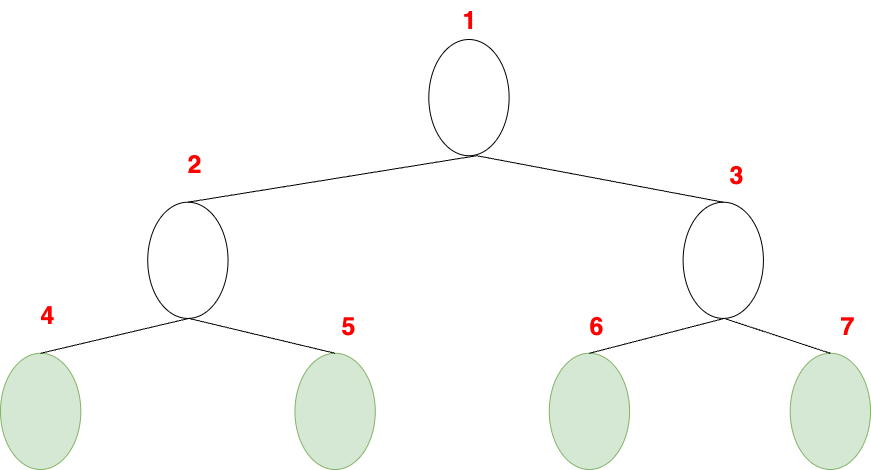
리프노드가 2ⁿ개 일때, 완전이진트리의 노드의 개수는 2ⁿx 2 -1 이다. 위 그림의 완전이진트리는 리프노드 개수가 4이다. 4*2-1 은 7이므로 완전이진트리의 노드의 개수는 7이다.
리프노드가 2ⁿ개가 아니라면 어떻게 될까?

리프노드 5개는 완전이진트리의 리프노드 4개와 리프노드 8개 사이에 있다. 그러므로 리프노드가 5개일 때, 이진트리의 총 노드의 개수는 아래 범위와 같다.
2²x 2 -1 < 리프노드가 5개인 경우 이진트리의 노드개수 < 2³x 2 -1
= ( 리프노드 4개 ) x 2 -1 < 리프노드가 5개인 경우 이진트리의 노드개수 < ( 리프노드 8개 ) x 2 -1
= ( 리프노드 4개 ) x 2 -1 < 리프노드가 5개인 경우 이진트리의 노드개수 < ( 리프노드 4개 ) x 2 x 2 -1
= 리프노드가 5개인 경우 이진트리의 노드개수 < ( 리프노드 4개 ) x 2 x 2 -1 < (리프노드 5개) x 2 x 2
= 리프노드가 5개인 경우 이진트리의 노드개수 < (리프노드 5개) x 4
그러므로
수열이 N개이면 리프노드가 N개이고
리프노드가 N개이면 세그먼트 트리는 최대 4xN 크기의 세그먼트 트리를 생성하면 된다.
tree = [0]*(len(arr)*4) #세그먼트트리
4xN은 안전한 계산을 위한 최대로 가능한 트리의 크기를 의미한다. 정확히 떨어지는 노드의 개수를 의미하지 않는다. 만약 정확히 떨어지는 노드의 개수를 구하는 방법이 궁금하면 링크를 참고하기를 바란다. ( https://eun-jeong.tistory.com/18 )
정리하면,
세그먼트 트리란 변경이 잦은 수열의 구간합을 O(logN)의 시간복잡도로 구현가능 하도록 만드는 알고리즘이다. 세그먼트 트리는 재귀호출로 구현되고 이진트리의 특성상 최대 노드 개수는 4xN개이다. 다음 포스팅에서는 실제 수열이 변경되었을때 어떻게 세그먼트 트리를 활용하는지 알아보겠다.
참고자료
41. 세그먼트 트리(Segment Tree)
이번 시간에 다룰 내용은 여러 개의 데이터가 연속적으로 존재할 때 특정한 범위의 데이터의 합을 구하는 ...
blog.naver.com
[자료구조] 세그먼트 트리 (Segment Tree) C++ 구현
Segment Tree 배열 A[1], ..., A[N]이 있을 때, 아래 문제를 생각해보자. [문제 1] 순서쌍 (i, j)에 대하여 A[i], ... ,A[j] 중 최솟값을 찾는 경우를 생각해보자. A[i]부터 A[j]까지 순회하면서 찾는 것이 가장 단
eun-jeong.tistory.com
'문제풀이 > 알고리즘' 카테고리의 다른 글
| [Alogorithm] 세그먼트 트리( Segment Tree ) 구간합 구하기 ( + BOJ2042 ) With Python,JAVA (0) | 2023.06.26 |
|---|---|
| [Algorithm] 이분그래프(Bipartite Graph) ( + BOJ1707 ) (0) | 2023.06.23 |
| [Algorithm] 위상정렬 (Topology Sort)이란? (0) | 2023.05.25 |
| [Algorithm] 크루스칼 알고리즘(Kruskal Algorithm)이란? (0) | 2023.05.24 |
| [Algorithm] 무방향그래프에서 싸이클 찾기 (0) | 2023.05.23 |