
1753번: 최단경로
첫째 줄에 정점의 개수 V와 간선의 개수 E가 주어진다. (1 ≤ V ≤ 20,000, 1 ≤ E ≤ 300,000) 모든 정점에는 1부터 V까지 번호가 매겨져 있다고 가정한다. 둘째 줄에는 시작 정점의 번호 K(1 ≤ K ≤ V)가
www.acmicpc.net
◎ 문제풀이
노드와 노드를 이동하는데 최단거리를 구하는 문제이다. 비용이 동일하면 BFS 알고리즘이 적절하지만 노드와 노드 사이의 비용이 상이하므로 최단경로를 구하는 알고리즘을 사용해야 한다. 특정한 시작점이 주어지고 모든 간선의 비용이 양수라면 다익스트라 알고리즘으로 최단경로를 계산한다.
[Algorithm] 다익스트라 알고리즘(Dijkstra)이란?
다익스트라 알고리즘(Dijkstra) 다익스트라 알고리즘은 특정지점에서 다른지점으로 가는 최단경로를 구하는 알고리즘이다. 다익스트라 알고리즘은 그리디(Greedy) 알고리즘 기반으로 한다. 그리디(
lordofkangs.tistory.com
다익스트라 알고리즘의 개념은 위 포스팅을 참고하기를 바란다. 다익스트라 알고리즘은 Greedy 알고리즘 성격이 있다. 최단경로를 구하는 과정에서 가장 최소 비용의 노드를 먼저 탐색해야 한다. 탐색을 단순히 for문으로 구현하면 시간복잡도가 올라가니 우선순위큐를 이용하여 시간복잡도를 줄인다.
[Algorithm] 개선된 다익스트라 알고리즘
[알고리즘] 다익스트라 알고리즘(Dijkstra)이란? 다익스트라 알고리즘(Dijkstra) 다익스트라 알고리즘은 특정지점에서 다른지점으로 가는 최단경로를 구하는 알고리즘이다. 다익스트라 알고리즘은
lordofkangs.tistory.com
우선순위큐를 활용한 다익스트라 알고리즘 개념은 위 포스팅을 참고하기를 바란다. 이 문제를 풀면서 두 가지 실수를 했다.
1. 인접리스트를 HashMap으로 구현하였다.
2. 방문처리를 잘못하여 지속적인 메모리 초과가 발생하였다.
1. 인접리스트를 HashMap으로 구현하였다.
인접리스트를 HashMap으로 구현하고 싶었다. 인접한 노드의 인덱스를 key로, 인접한 노드로 가는 비용을 value로 하면 더 직관적이지 않을까 하는 생각에서였다. 그러나 이는 다익스트라 알고리즘의 무지에서 비롯된 생각이었다. 인접노드로 가는 간선이 1개만 있는 경우 가능하지만 2개가 되면 충돌이 발생한다.
1번 노드에서 3번 노드로 가는데, 비용이 3이 드는 간선이 있고
1번 노드에서 3번 노드로 가는데, 비용이 5가 드는 간선이 있다.
key가 3으로 동일하고 비용은 다르니 충돌이 발생한다. 그러므로 List 자료구조로 구현해야 한다.
2. 방문처리를 잘못하여 지속적인 메모리 초과가 발생하였다.
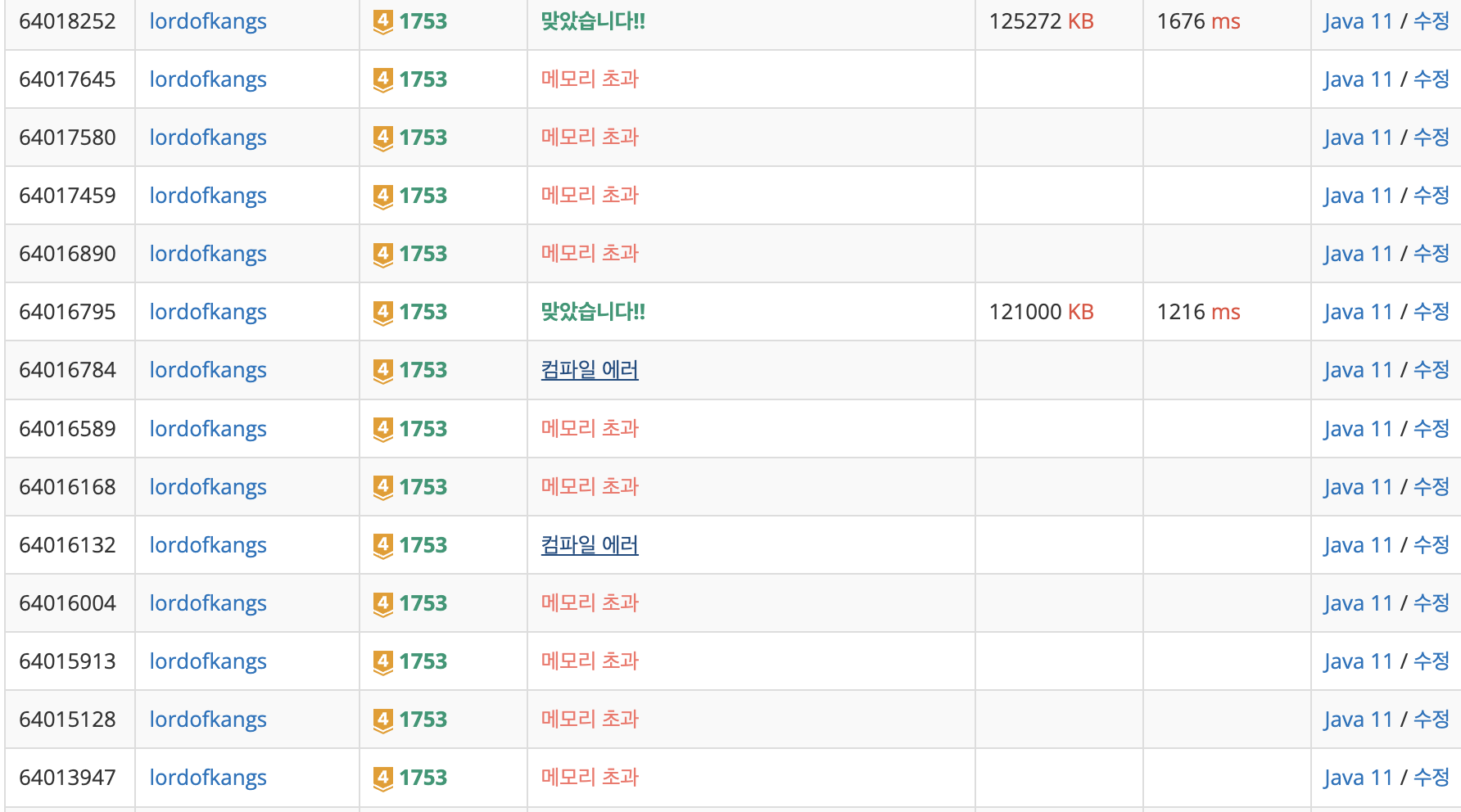
메모리 초과 때문에 개고생한 문제이다.
다른 분들의 풀이를 보면 다익스트라 알고리즘을 인접행렬로 풀면 노드의 개수가 최대 20,000개여서 메모리 초과가 발생하다고 하는데, 나는 처음부터 인접리스트로 풀었기에 원인을 찾는데 어려움이 있었다. 원인은 미숙한 방문처리에 있었다. 다익스트라 알고리즘은 간선의 비용이 양수이기에 이미 방문한 곳을 재방문하면 최단경로가 아니다. 그래서 재방문을 막는 로직이 필요하다. 나도 이 개념을 인지하고 있었지만 불완전하게 처리했다.

다익스트라 알고리즘은 최단경로 알고리즘으로 여러 경로 중 최단경로를 구해야 한다. 그러므로 경로를 객체화한 클래스가 필요한데, 그것이 Edge이다. Edge에는 다음 이동할 인덱스와 시작점부터 다음 인덱스까지 가는데 걸리는 비용을 담고 있다. 다시 말해, 한 가지 경로를 데이터화한 객체가 Edge이다.
우선순위큐를 사용하여, Edge 중에 특정 노드까지 가는데 가장 적은 비용이 드는 Edge(경로)부터 가져와 탐색한다.(Greedy) 우선순위큐 내부에서는 가장 적은 비용이지만 전체에서는 아닐 수 있다. 그러므로 해당 경로(Edge)가 노드에 최적의 비용으로 접근한 것인지 검사해야 한다. 만약 이미 다른 경로가 최적의 비용으로 접근했다면 해당 Edge의 탐색을 종료한다. 앞서 말했듯, 다익스트라 알고리즘은 그리디 알고리즘이다. 최적해가 아닌 경로는 버려 탐색의 경우의 수를 줄여야 한다. 이는 백트래킹이기도 하다.
내가 잘못한 부분은 Edge 생성과정에서 아무런 제약을 두지 않았다는 점이다. 다익스트라 알고리즘은 Edge의 비용이 낮은 노드부터 우선 탐색하는 알고리즘이다. 그러나 이미 낮은 비용으로 탐색이 완료되었는데, 다시 해당 노드를 재방문하는 간선이 존재할 수 있다. 만약 Edge 생성에 아무런 제약이 없다면 간선은 무의미한 Edge객체를 만들어 불필요한 메모리와 불필요한 로직이 소모될 수 있다.

내가 메모리 초과가 발생한 이유는 여기에 있다.
어차피 무의미한 Edge는 최적의 비용이 아니니 걸러진다고 생각했다. 그러나 간선의 개수는 최대 30만개이다. 초기 최대 30만개의 Edge객체가 생성된다. 그리고 30만 Edge 각각이 인접노드에 접근할 때, 새로 갱신된 경로(Edge)가 새로이 생성되어 우선순위 큐에 들어간다.한마디로 기하급수적으로 증가한다. 정확한 메모리 계산은 못하지만 한 가지 확실한 것은 백트래킹으로 경우의 수를 줄여도 메모리초과가 난다는 것이다. 그러므로 인접노드를 탐색하여 Edge를 생성할 때, 이미 방문한 노드로 이동하는 경로(Edge)는 생성을 막아야 한다. 그래야 메모리 초과가 발생하지 않는다.
◎코드
import java.io.*;
import java.util.*;
//BOJ1753 최단경로
public class Main {
public static PriorityQueue<Edge> priorityQueue = new PriorityQueue<>(); // 우선순위큐
public static int[] dist; // 최단경로테이블
public static boolean[] visited; // 방문여부테이블
public static List<Edge>[] nextNodes; // 인접노드테이블
//Edge 이동경로 데이터를 담은 객체
public static class Edge implements Comparable<Edge> {
int index; //이동할 인접노드 인덱스
int cost; // 이동할 경우 인접노드까지 드는 비용
public Edge(int index, int cost) {
this.index = index;
this.cost = cost;
}
@Override
public int compareTo(Edge o) {
return this.cost - o.cost;
}
}
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st = new StringTokenizer(br.readLine());
int v = Integer.parseInt(st.nextToken());
int e = Integer.parseInt(st.nextToken());
int start = Integer.parseInt(br.readLine());
nextNodes = new ArrayList[v+1];
dist = new int[v+1];
visited = new boolean[v+1];
for(int i=1;i<=v;i++){
nextNodes[i] = new ArrayList<Edge>();
dist[i] = Integer.MAX_VALUE;
}
//인접노드테이블 초기화
for(int i=0;i<e;i++){
st = new StringTokenizer(br.readLine());
int index = Integer.parseInt(st.nextToken());
int nextIndex = Integer.parseInt(st.nextToken());
int cost = Integer.parseInt(st.nextToken());
nextNodes[index].add(new Edge(nextIndex,cost));
}
// 다익스트라 알고리즘 시작
dijkstra(start);
//출력
StringBuilder sb = new StringBuilder();
for(int i=1;i<=v;i++){
if( dist[i]== Integer.MAX_VALUE) sb.append("INF").append("\n");
else sb.append(dist[i]).append("\n");
}
bw.write(sb.toString());
bw.flush();
bw.close();
br.close();
}
public static void dijkstra(int start){
//시작점
dist[start] = 0;
visited[start] = true;
List<Edge> next = nextNodes[start];
priorityQueue.add(new Edge(start,0));
while(!priorityQueue.isEmpty()){
Edge edge = priorityQueue.poll(); // 우선순위큐에서 가장 낮은 비용의 이동경로 객체 Edge 가져오기
if( edge.cost > dist[edge.index] ) continue; // 최적 비용 여부 탐색 ( 백트래킹 )
dist[edge.index] = edge.cost; // 최적의 비용으로 초기화
for (Edge nextEdge : nextNodes[edge.index]) { // 인접노드 탐색
if(!visited[nextEdge.index]){ // 이미 방문된 노드인 경우 X
int nextDist = dist[edge.index] + nextEdge.cost; // 이동경로 데이터 최신화
priorityQueue.add(new Edge(nextEdge.index,nextDist)); // Edge 생성하여 우선순위큐에넣기
}
}
visited[edge.index] =true; // 탐색완료
}
}
}
'문제풀이' 카테고리의 다른 글
| [PS] BOJ10815 숫자카드 ( BinarySearch ) with JAVA (0) | 2023.07.26 |
|---|---|
| [PS] BOJ16929 Two Dots ( DFS ) with JAVA (0) | 2023.07.26 |
| [PS] BOJ2156 포도주 시식 ( DP ) with JAVA,Python (0) | 2023.07.24 |
| [PS] BOJ2352 반도체 설계 ( LIS ) with JAVA (0) | 2023.07.21 |
| [PS] BOJ2805 나무 자르기 ( BinarySearch ) with JAVA (0) | 2023.07.21 |