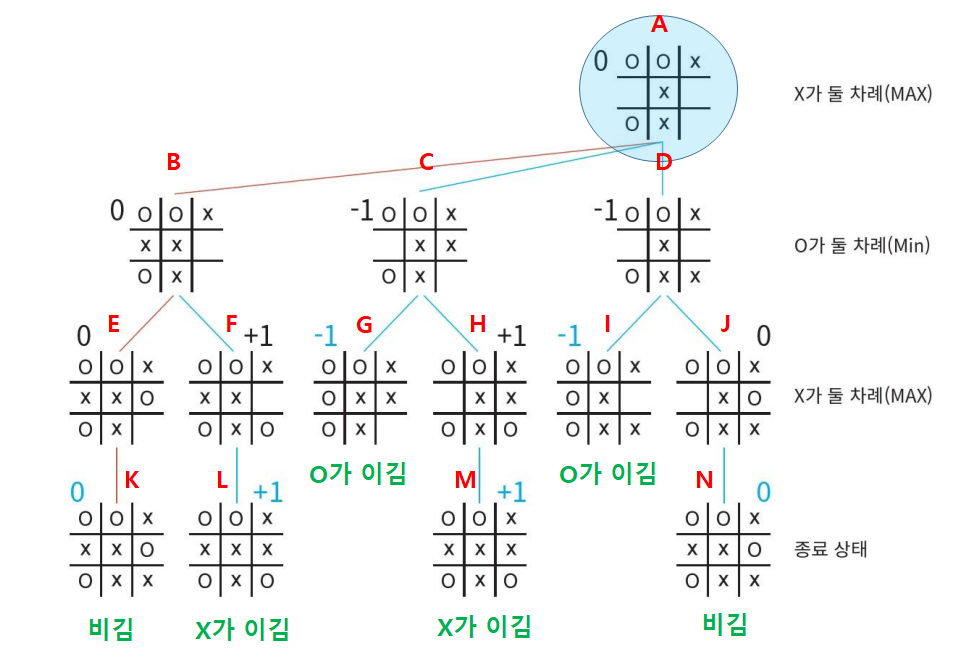
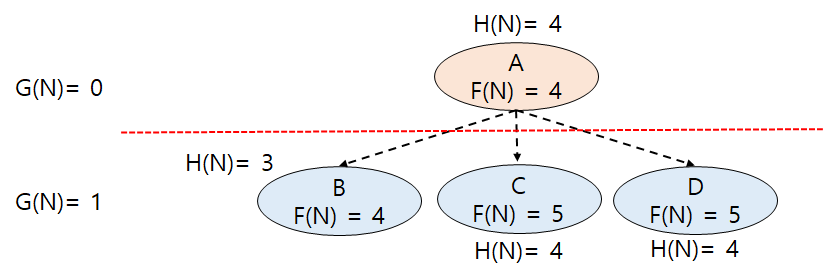
지금껏 포스팅했던 '탐색'으로 구현한 인공지능은 절차적 코드를 사용한다. 그러나 지능은 '탐색'으로만 구현되지 않는다. 전문가 시스템은 코드가 아닌 규칙으로 표현된 지식을 이용하여 좀 더 복잡한 문제를 해결한다. 전문가 시스템 이미 습득한 지식을 이용하여 새로운 사실을 추론하는 방법이다. 생성규칙(Production Rules) 데이터 : 사실 ( True ) ( ex. 신호등, 빨간색 ) 정보 : 의미 있는 사실 ( True ) ( ex. 신호등이 빨간색이다. ) 지식 : 추론을 위한 정보 ( True or False ) ( ex. 신호등이 빨간색이면 멈추어야 한다. ) EX. ) 자동차가 움직이지 않는다. AND 연료탱크가 비웠다. ( 상황 ) THEN 자동차에 연료를 급유한다. ( 결론 ) ( 상황..